
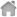 当前位置:
当前位置:



|
主题:[分享]科汛采集插件使用教程(不知道能不能申精) [收藏主题] | 转到: |
 相信有很多朋友都像畅想网络的宾哥一样使用科汛系统, 今天刚好有一位朋友请教宾哥如何用科汛采集信息, 宾哥也找了找,的确没有看到有采集的教程, 宾哥本着授人与鱼不如授人于渔的态度连夜(宾哥今天加班下班回到家,就八点多钟了哦)写了一个科汛采集的教程,以供各位新手朋友学习,也供各位老鸟们指点。
本教程以kesioncmsX1.5为例 第一步:应用-采集插件-采集项目管理:(如图1)
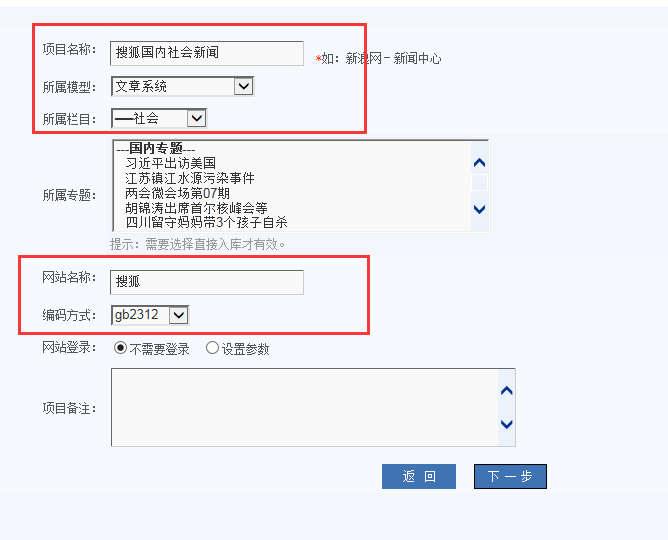
图1 完成图1中的操作后,会出现 图2中的表单,宾哥标识出来的,是必填的,尤其是编码,需要根据需要采集的网站来选择, 宾哥以搜狐国内社会新闻为例设置采集规则
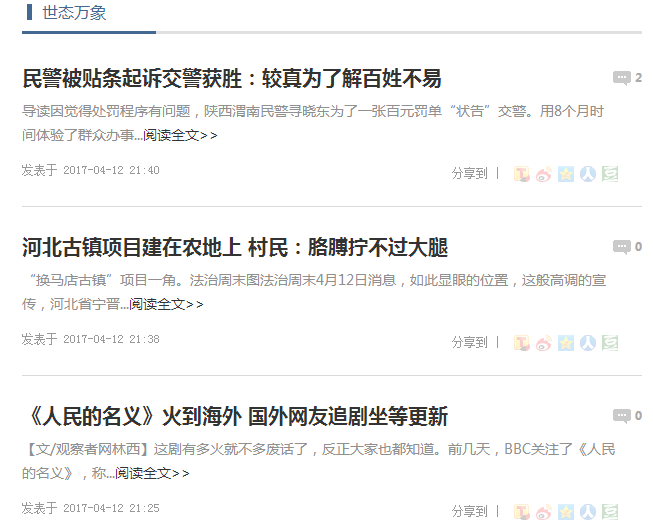
图2 然后点一步,又给我们一个表单,,我们需要根据网站的规则来让程序抓取需要采集的范围, 宾哥以搜狐国内社会新闻为例设置采集规则,网址 http://news.sohu.com/guoneixinwen.shtml 我们要采集的是图3中的文章列表,
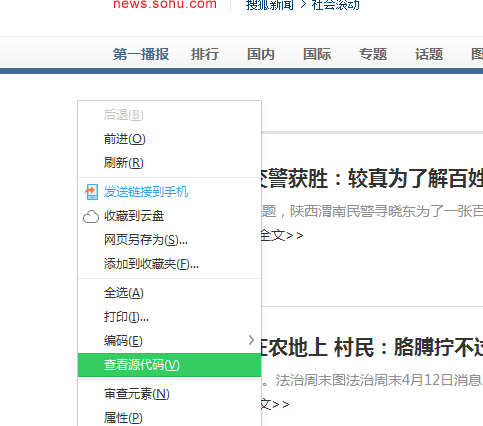
图3 鼠标放在网页的空白位置 ,右击,查看源代码 (宾哥使用的是360浏览器,)如图4所示
图4 查看源代码之后,我们看到的全是HTML, 无从下手, 不过, 还是有技巧的,那是找列表开始的地方,我们看到列表上方有一个世态万象 四个字 我们就从HTML里面搜这几个字, 用浏览器快捷键 Ctrl+F 来找, 一定要记住这个快捷键,因为以后会经常用到 , 如宾哥浏览器, 找到了,而且四个字,是唯一的, 就好找好了, --------------------- 不要怪宾哥小气,整理了贴子,也是为了让大家顶的嘛 ---------------------  以下内容只有回复后才可以浏览,请先登录! 以下内容只有回复后才可以浏览,请先登录!各位粉丝可进群【网站梦工厂】相互交流学习,QQ群号 107315765 在群里找宾哥解决问题, 宾哥只要不忙, 有求必应的~ |
|
要么好好的活,要么赶紧去死! | |
 支持(0) | 支持(0) |  反对(0) 反对(0)
 顶端 顶端  底部 底部
|








| <上一主题 | 下一主题 > |